

Dynamically Modifiable Collision Map for Real-Time Games using Quadtrees
In Dusky Depths we made the map terrain completely destroyable — just like in many artillery games. This, however, posed us some unique challenges, since Dusky Depths is a fast-paced action game with much more complex maps compared to (turn-based) artillery games.

Our requirements can be summarized as follows:
- Big Maps
Players should be allowed to make the map as gargantuan as they want as long as the size still makes somewhat sense for the gameplay of Dusky Depths, e.g. 20,000 x 20,000 pixels. - Health Points per Pixel
Every pixel on the collision map should have health points so that we can partially damage terrain, for example by means of explosions. - Fast read and write access for individual pixels
We need fast read access so that the map physics bodies can be quickly updated when pixels change their value on the map. Fast write access is also needed when we change the HP of a pixel. - Fast read access for rectangular areas on the collision map. The GPU needs to know which area on the map still exist because we don’t want it to draw terrain that has 0 HP. For that we need to send the visible area of the collision map to the GPU. Additionally, we also need this because we don’t want to send the whole map to the player at once. Instead, we want to stream the map to the player in order to allow the player to start playing on a server as quickly as possible. The server will accomplish this by reading rectangular areas on the collision map and sending those to the connected players.
- Easy AI waypoint creation.
For the AI of mobs and bots, we need to generate so-called waypoints. Waypoints are points that are connected to each other on the map. Each waypoint connection represents a path that the AI can freely traverse without a wall blocking the way. Without them, the AI wouldn’t know where it can travel without hitting a wall. - Minimal memory space required
The collision map needs to be small enough to fit in a computer’s RAM. This can be a problem because virtual servers (the typical game server hosting packages) usually don’t have a lot of RAM.
Now the question is: What kind of data structure would be the most suited for a collision map that meets those requirements?
Naive Idea #1: The 2-dimensional array.
An array is a data type that can hold multiple variables at once within a fixed and continous area of the RAM. For example, an array with the size “4” contains 4 different cells in which variables can be stored. Each cell can be accessed with a unique index integer. In the programming language C#, the first cell of the array would have the index “0”, the seond one “1”, the third one “2” and so on.
While such a normal array could be described as a row of variables, a 2D array is a table of variables. That means the size of a 2D array consists of width and height. The index would consist of two integers and not just one, with the first integer being the row and the second one being the column in which the cell resides.

The collision map could be stored in such a 2D array. The index of each cell would then be the x and y coordinates of a map pixel, while the value of a cell would be a single byte (an integer with a value between 0-255) that represents the HP of a pixel.
Arrays are very fast, so there shouldn’t be any performance problems with this idea. There are two issues with this solution however:
- Generation of AI waypoints is complicated. We would need to analyze which areas are empty on the map and within those areas uniformly spread the waypoints. See also: Countour tracing algorithms.
- The array would need to be big enough to contain every single pixel in the collision map. For example, a map with the size 20,000 x 20,000 pixels would consume at least 400MB of RAM.
With those issues in the way, we’ll need a different approach.
Naive Idea #2: The associative array (DictionaryMap)
An associative array (also known as dictionary) is a data type that contains key-value pairs. Each key in the dictionary is unique and each key is associated (paired) with a value (variable). Those key-value pairs can be dynamically added and removed from the dictionary. Since dictionaries are a bit complicated, I won’t explain in detail how they work, but you can read more about them here.

For the collision map, we would let the key of a key-value pair be a tuple consisting of the x and y coordinates of a pixel. The value would then be a byte which represents the health of a pixel.
The advantage of the dictionary is that we don’t have to save pixels with 0 HP. We can simply assume that if a key does not exist in the dictionary, the HP of that pixel is 0. This may save us a considerate amount of memory, depending on the map. However, it should be noted that we need to save the tuple together with the byte which is why this idea might actually consume even more memory than the array. Additionaly, the read/write performance of a dictionary would also be unacceptable. When the programmer would want to access a pixel on the collision map, they would pass a tuple with the x and y coordinates of the pixel to the dictionary. The dictionary would then have to compute the hashcode of this key, which can be ultimately 100 times slower than direct array access.
Better Idea: The dictionary of 2D arrays (ChunkMap)
For this idea we combine the previous two ideas. We subdivide the collision map into chunks. Each of those chunks is contains a 2D array with equal height and width. Those chunks are then added to the dictionary, with the key being the chunk’s positional offset divided by the chunk size.

To access a pixel on the collision map, the pixel position would be passed to the ChunkMap. The ChunkMap would then first determine the dictionary key of the chunk which contains the pixel. This is done simply by dividing the position with the width/height of a chunk. Afterwards, the key is passed to the dictionary which will then return the desired chunk. The last step would then be to access the desired pixel in the returned chunk’s array.
To make this solution fast, the ChunkMap caches the chunk that has been used last. That way, dictionary lookups can be mostly avoided when accessing the collision map, since very often the pixels that are accessed are near each other and thus are located on the same chunk.
Additionally, we can save a huge amount of memory by using a custom data type for the chunks instead of just using the array:
class ChunkData
{
// Boolean value that states whether the chunk is completely filled with a single HP value.
bool isSolid;
// The pixel HP value with which the chunk is filled with if isSolid is true.
byte solidFill;
// The 2D array which contains the individual pixel HP values. Only used if isSolid is false.
byte[,] collisionData;
}If we know that a chunk has been completely filled with the same pixel HP value, we can set the collisionData of the ChunkData to null to free memory. Then we will set isSolid to true and solidFill to the aforementioned HP value. That way, when a lookup occurs, the ChunkMap will first check if isSolid is true and subsequently just return solidFill instead of looking up the value in the array.
When we want to change the HP of a pixel, we will set the isSolid bool of the chunk on which the pixel is located immediately to false. If the collisionData array didn’t exist, we will create it now and set all of its byte to the value of solidFill, except for the pixel that we want to change. After a write operation, we won’t know for sure if the chunk is solid or not, so for now we’ll assume that it isn’t. Then we will add the chunk’s key to a list that contains all chunks that have been written to. Periodically, we will iterate over this list to check if those chunks are solid or not and subsequently update their isSolid and solidFill values. Chunks that have been checked will then be removed from that list.
Now the questions is, how big will we have to make the chunks? Bigger chunks would waste more memory compared to smaller chunks, since they inevitably encompass a lot of otherwise as isSolid marked space. Additionally, if we make the chunks small we’ll be able to directly use the positions of the chunks as waypoints for the AI, since, due to the isSolid boolean, we already know whether an area is empty or not. We cannot do this if the chunks are too big because the waypoints generated that way would only exist in very big areas; small empty areas wouldn’t be traversed by the AI. The issue with small chunks however is that we’ll have a lot of dictionary cache misses. Thus, the performance would detoriate significantly.
So the last question is: can we somehow have small chunks and yet also have few dictionary cache misses?
Our solution: The dictionary of Quadtrees (QuadTreeMap)
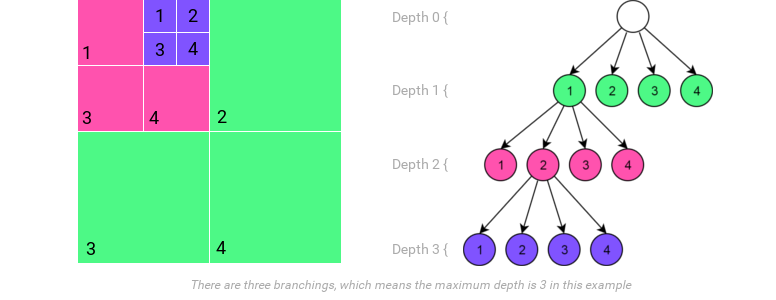
A quadtree is a tree data structure in which each node has 4 children. We use it to subdivide each chunk into 4 equally small child chunks. This will be done for each chunk until the maxmimum depth that we want is reached.
Just like for the ChunkMap, we’ll continue to use a cached dictionary. The ChunkData class however will be a bit different:
class ChunkData
{
// Boolean value that states whether the chunk is completely filled with a single HP value.
bool isSolid;
// The pixel HP value with which the chunk is filled with if isSolid is true.
byte solidFill;
// The 2D array which contains the individual pixel HP values. Only used if isSolid is false.
byte[,] collisionData;
// Child nodes of the chunk.
ChunkData[] subChunks;
// Depth of the node within the tree. This is basically the number of ancestors this node has.
int depth;
}The ChunkData will now have an array of ChunkData which contains the 4 children of it as seen in the illustration. This is called a recursive data structure which means that it contains variables that are of the same type as itself. Furthermore, we will have the collisionData always be null (empty) unless the node’s depth is equal to the maximum tree depth and the node’s isSolid is false.

To explain how it works, we’ll explain how a pixel on the collision map would now be accessed. The first steps are the same as in the ChunkMap. The programmer would pass the pixel position to the QuadTreeMap. The QuadTreeMap would first determine the dictionary key of the chunk which contains the pixel. This is done simply by dividing the position with the width/height of a chunk. Afterwards, the key is passed to the dictionary which will then return the desired chunk. But now we can’t just access the chunk as-is. We might have to traverse the quadtree that this chunk forms. The following steps will now be executed:
- Check if
isSolidis true. If it is, then we can just return thesolidFillbyte. - Otherwise, check if the node’s
depthis equal to the maximum depth. If we have reached the maximum tree depth, then thecollisionDatawill not be null and we will have our desired pixel in it. We return the pixel value and then we’re finished. - Otherwise, this means that the
ChunkData’sdepthis not the maximum tree depth.ChunkDatathat are not at maximum depth always have theircollisionDataset to null. That is why we need to repeat those steps with one of theChunkDatastored in thesubChunks. We determine which one we need by computing the position and size of the child chunks. Looking at the illustration, it is trivial to determine the position and size of a child node. The child chunk that contains the pixel’s position is the one for which we will repeat those 3 steps.
Summarized: We traverse the quadtree until we either find a solid ChunkData or a ChunkData with maximum depth.
When writing on the quadtree collision map, we need to almost do the same thing we did for writing on the ChunkMap - setting isSolid to false. But now we also need to immediately set isSolid to false for all ancestor nodes as well.
And again, after the write operation, we won’t know for sure if the chunk is solid or not, so for now we’ll assume that it isn’t. We’ll add the chunk’s key to a list that contains all chunks that have been written to. Periodically, we will iterate over this list to check if those chunks are solid or not and subsequently update their isSolid and solidFill values. But now we also need to check if the child nodes of a chunk are isSolid as well before setting a chunk’s isSolid to true. That doesn’t apply for chunks whose depth is equal to the maximum depth of course, since they don’t have any child nodes.
Now let’s check if this solution fulfills all of our requirements:
- Big Maps
✓ Maps can be virtually infinitely big. - Health Points per Pixel
✓ Every pixel has its HP represented by a byte. - Fast read and write access for individual pixels.
✓ It isn’t as fast as directly accessing an array, but it’s still fast enough for our purposes. Caching helps us a lot. - Fast read access for rectangular areas on the collision map.
✓ Just like the previous requirement, it’s fast enough. - Easy AI waypoint creation.
✓ AI waypoint generation is trivial. We can easily insert points in the map region of every chunk that hasisSolidset to true andsolidFillto 0. - Minimal memory space required
✓ The memory usage is minified since we don’t have to allocate arrays for collision map regions whoseisSolidvalue is set to true.
As you can see, it meets all of our requirements! Perfect. Now let’s see the QuadTreeMap in action:
Further performance optimizations for the QuadTreeMap
- Use memset or the equivalent of your programming language or game engine. For .net languages, that would be the
System.Runtime.CompilerServices.Unsafe.InitBlockmethod. Old .net versions don’t have this method, so you might need to construct a method by yourself using theInitblkCIL instruction. - Use memcpy/memmove or the equivalent of your programming language or game engine. For .net languages, that would be the
System.Runtime.CompilerServices.Unsafe.CopyBlockmethod. If unsafe code is not available or if you’re using an old .net version, you can also use theArray.Copymethod. - Use flat 1D arrays instead of 2D arrays. Accessing 2D arrays is slower than accessing 1D arrays due to additional bounds checks.
- Use bitwise operations to avoid expensive branch mispredictions caused by conditionals if possible.
- Use object pools so that you don’t have to re-allocate arrays when a chunk gets a new array.
- If you use a tile-based map it would be possible to deduplicate the arrays of chunks with the same tile.